$ sphinx-quickstart > Root path for the documentation [.]: > Separate source and build directories (y/n) [n]: > Name prefix for templates and static dir [_]: > Project name: TIL > Author name(s): Yunseop Song > Project version []: 1.0 > Project release [1.0]: > Project language [en]: > Source file suffix [.rst]: > Name of your master document (without suffix) [index]: > Do you want to use the epub builder (y/n) [n]: > autodoc: automatically insert docstrings from modules (y/n) [n]: > doctest: automatically test code snippets in doctest blocks (y/n) [n]: > intersphinx: link between Sphinx documentation of different projects (y/n) [n]: > todo: write "todo" entries that can be shown or hidden on build (y/n) [n]: > coverage: checks for documentation coverage (y/n) [n]: > imgmath: include math, rendered as PNG or SVG images (y/n) [n]: > mathjax: include math, rendered in the browser by MathJax (y/n) [n]: > ifconfig: conditional inclusion of content based on config values (y/n) [n]: > viewcode: include links to the source code of documented Python objects (y/n) [n]: > githubpages: create .nojekyll file to publish the document on GitHub pages (y/n) [n]: > Create Makefile? (y/n) [y]: > Create Windows command file? (y/n) [y]: n
Finished: An initial directory structure has been created.
You should now populate your master file ./index.rst and create other documentation source files. Use the Makefile to build the docs, like so: make builder where"builder" is one of the supported builders, e.g. html, latex or linkcheck.
$ make html Running Sphinx v1.6.5 making output directory... loading pickled environment... not yet created building [mo]: targets for 0 po files that are out of date building [html]: targets for 1 source files that are out of date updating environment: 1 added, 0 changed, 0 removed reading sources... [100%] index looking for now-outdated files... none found pickling environment... done checking consistency... done preparing documents... done writing output... [100%] index generating indices... genindex writing additional pages... search copying static files... done copying extra files... done dumping search index in English (code: en) ... done dumping object inventory... done build succeeded.
Build finished. The HTML pages are in _build/html.
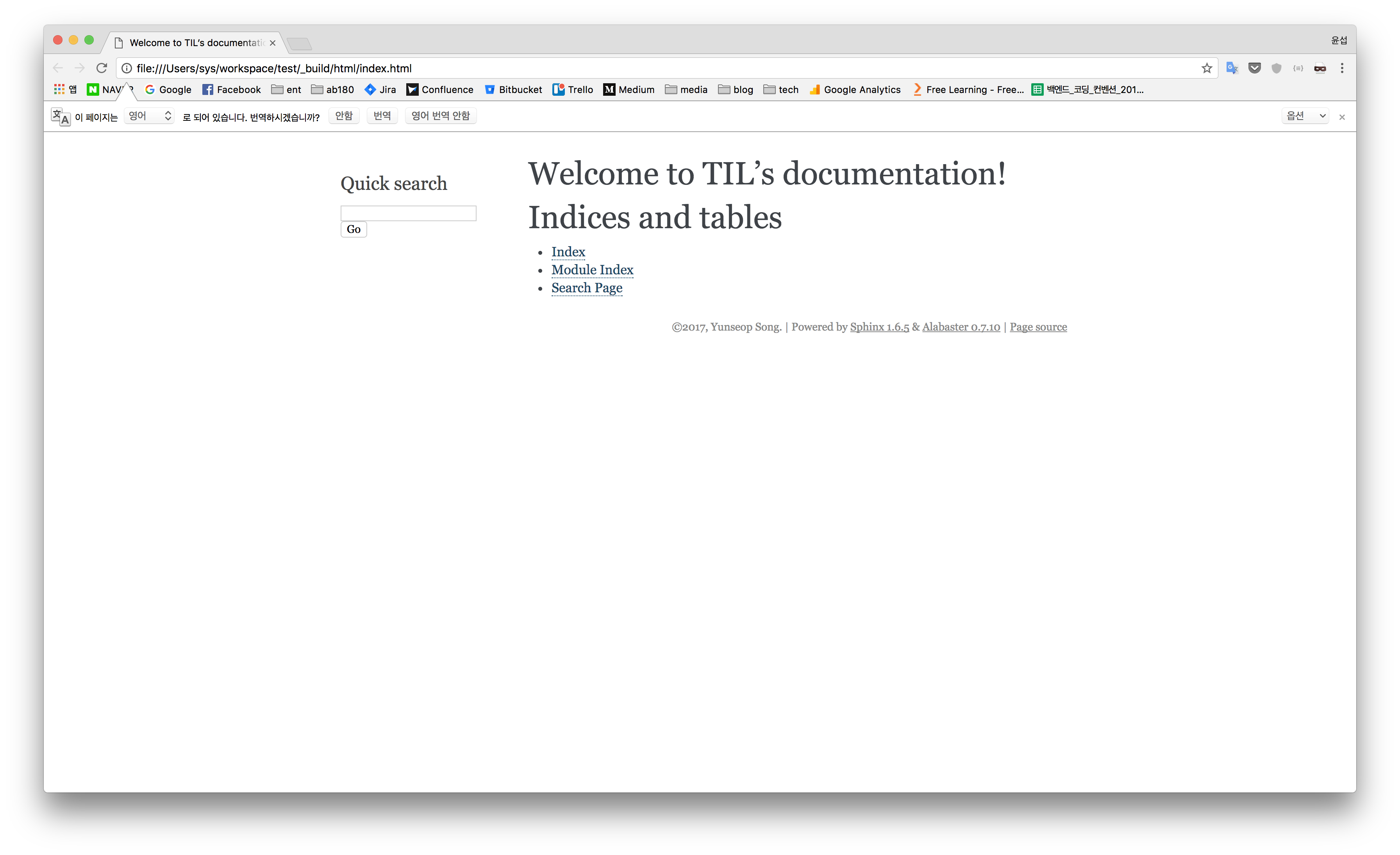
그리고 _build/html/index.html을 열면 다음처럼 깔끔한 페이지를 볼 수 있다.
하지만 이 상태라면 마크다운 문서는 보여지지 않는다. Sphinx에서 마크다운을 사용하려면 문서에 나온대로 recommonmark라는 패키지를 사용해야한다.
일단 recommonmark를 설치하자.
1
$ pip install recommonmark
그리고 conf.py 파일을 수정하자.
1 2 3 4 5 6 7
from recommonmark.parser import CommonMarkParser
source_parsers = { '.md': CommonMarkParser, }
source_suffix = ['.rst', '.md']
그리고 Sphinx에서 바라보는 master_doc인 index.rst에 toctree를 추가해야한다. index.rst에 toctree를 추가하는 이유는 Markdown에서 지원을 하지 않기 때문에 약간의 편법…(사실 어떻게 하는지 잘 모르겠다.)
1 2 3 4 5 6 7 8
.. toctree:: :caption: TOC: :glob: :titlesonly:
mysql/* python/* vim/*
이렇게 추가를 하고 다시 make html을 하면 TOC가 제대로 추가된 것을 확인할 수 있다.
배포를 해봅시다.
Sphinx를 사용해 TIL 페이지는 완성되었다.
이제 배포만 남았는데 어디로 어떻게 배포할 지를 결정해야 했는데 구글링을 해보던 중 아주아주 좋은 것을 발견했다.
Python WSGI Application을 배포하기 떄문에 코드의 변경없이 Django, Flask와 같이 WSGI Application을 그대로 배포할 수 있다.(내 생각에 이게 가장 큰 장점이 아닐까 싶다.)
서버리스로 가기 위한 최소한의 셋팅을 다 알아서 해준다. 프로젝트를 압축하여 Lambda에 배포하고 API Gateway에서 Lambda를 사용할 수 있게 알아서 설정해준다. 또한 몇가지 설정만 추가한다면 다른 AWS의 서비스도 사용가능하다.
API Gateway의 Stage를 구성하기가 매우 쉽다. 그냥 설정파일에 stage용 설정을 추가하기만 하면 끝이다. 도메인까지 설정해서 쓰면 요긴하기 쓸 수 있다.
하지만 뭐든 그렇듯 물론 장점만 있지는 않다. 내가 생각하는 Zappa의 단점은
모니터링이 힘들다. New Relic을 붙여서 사용하려고 했더니 뭔가 로그가 불규칙적으로 들어온다. 문제가 뭔지 잘 모르겠다.(해결방법을 아시는 분 있다면 공유좀…)
그래서 AWS X-Ray를 쓰려했더니 Node.js, Java, .Net만 지원하다고 한다. 그래서 찾아보니 xrayvision이라는 프로젝트가 있어서 사용 중이다. 하지만 X-Ray가 모니터링 하기에 뭔가 부족한 느낌의 서비스인 것 같다.
아직 성숙한 프로젝트가 아니다. 그렇다고 막 버그 투성이인 프로젝트는 아니다. 그럼에도 단점에 적은 이유는 Zappa로 배포하고 테스트를 진행하던 중 뭔가 안되는 부분이 있었는데, 알고보니 아직 지원을 안하는 것이었다. 하지만 다행히(?) 내가 삽질하던 그즈음에 누군가 PR를 보냈고 머지 되어 지금은 잘 사용하고 있다. 이런것을 보면 오히려 좋은 오픈소스 프로젝트에 기여할 기회가 많다 고 생각할 수도 있다.
Zappa is a system for running server-less Python web applications on AWS Lambda and AWS API Gateway. This `init` command will help you create and configure your new Zappa deployment. Let's get started!
Your Zappa configuration can support multiple production stages, like 'dev', 'staging', and 'production'. What do you want to call this environment (default 'dev'):
AWS Lambda and API Gateway are only available in certain regions. Let's check to make sure you have a profile set up in one that will work. Okay, using profile default!
Your Zappa deployments will need to be uploaded to a private S3 bucket. If you don't have a bucket yet, we'll create one for you too. What do you want call your bucket? (default 'zappa-8wjmc0weu'):
What's the modular path to your app's function? This will likely be something like 'your_module.app'. Where is your app's function?: app.__init__.app
You can optionally deploy to all available regions in order to provide fast global service. If you are using Zappa for the first time, you probably don't want to do this! Would you like to deploy this application globally? (default 'n') [y/n/(p)rimary]:
$ flake8 test.py test.py:3:1: E305 expected 2 blank lines after class or function definition, found 0 test.py:3:1: E402 module level import not at top of file test.py:3:1: F401 'os' imported but unused test.py:5:1: W391 blank line at end of file
Flake는 다양한 옵션과 함께 쓸수 있는데(특정 오류만 체크한다던지 등) cli에서 --와 옵션을 써줘서 사용하거나 Configuration File을 만들어서 사용할 수 있다.
Configuration File 은 전역으로 사용하기 위해 User 별로 설정할 수 있다.
Linux, OS X: ~/.config/flake8
Windows : ~\.flake8
또한 각 프로젝트 별로 사용하기 위해 프로젝트의 상위 디렉토리의 setup.cfg, tox.ini, .flake8 와 같은 파일을 사용할 수 있다.
둘 중의 하나의 방법으로 아래의 내용으로 설정 파일을 만들자.
1 2 3 4 5 6 7
[flake8]
ignore = E501, E402, E261
exclude = .git, __pycache__
count = True
이제 다시 flake8을 실행하면 메세지의 변화가 생긴다.
1 2 3 4 5
$ flake8 test.py test.py:3:1: E305 expected 2 blank lines after class or function definition, found 0 test.py:3:1: F401 'os' imported but unused test.py:5:1: W391 blank line at end of file 3
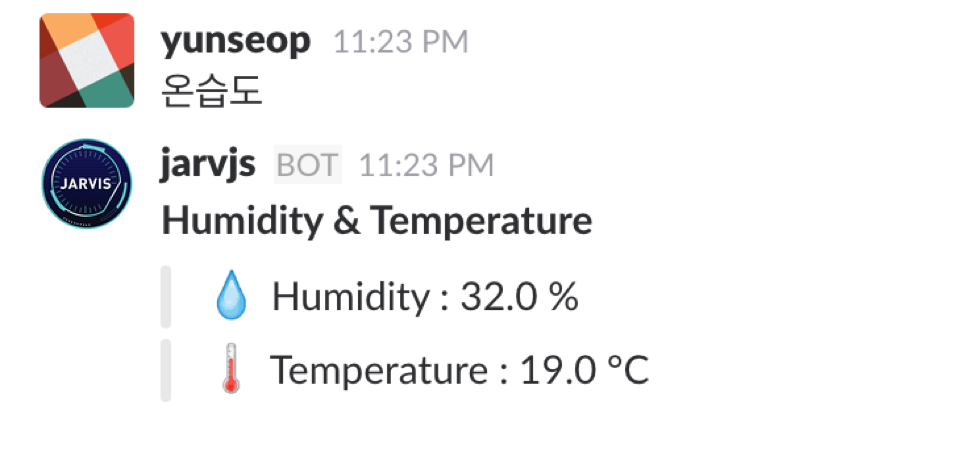
개발 중 에러가 발생하면 로그에 에러메세지가 뜨지만 슬랙에서는 아무런 반응이 없어서 이것이 오래 걸리는 작업이라 그런건지 에러가 난건지 알 수 없었다. 그래서 에러가 발생하면 에러 메세지를 슬랙으로 전송해 개발 효율을 높일수 있었다.
Django
봇 기능중에 온습도를 측정하는 기능이 있었는데 센서에서 값을 실시간으로 불러오면 시간이 조금 걸렸다. 그래서 어딘가에 주기적으로 기록하고 그 값을 가져오야 겠다 싶기도 했고, 옵습도 값 변화를 한눈에 보면 좋겠다싶어 웹 서버 하나를 만들어 그래프를 만들었다. 그래서 웹서버로 Django를 사용했다.
Django-crontab
온습도 값을 센서에서 읽어와 데이터베이스에 저장하는 스크립트를 crontab으로 하려했는데 찾아보니 Django-crontab이란것을 발견했다. 이것의 장점은 Django의 ORM기능을 그대로 사용할 수 있다는 것이다. 덕분에 아래와 같이 코드량이 매우 감소해 개발시간을 줄일 수 있었다. Django-crontab 역시 Github에 문서화가 잘 되어있어 사용법을 참고하면 된다.
1 2 3 4 5 6 7 8 9 10
import Adafruit_DHT from common import models from datetime import datetime